
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- bineary search
- 코딩테스트
- HTTP
- 해시
- rest api
- 캐싱
- 파이썬 오류
- 머신러닝
- 강화학습
- Merge sort
- post
- BOJ
- 자바
- 파이썬 알고리즘
- 지도학습
- 깊이우선탐색
- 딥러닝
- 알고리즘
- 백준
- 코딩
- 스택과 힙
- 이진탐색
- 프로그래머스
- 딕셔너리
- 오버라이딩
- 파이썬
- 너비우선탐색
- 비지도학습
- 코테
- 멱등
- Today
- Total
chae._.chae
02. [로지스틱 회귀] 이진분류 본문
분류하는 뉴런, 이진 분류
로지스틱 회귀(Logistic Regression)는 회귀를 사용하여 데이터가 어느 범주에 속할 확률을 0에서 1사이의 값으로 예측하고,
그 확률에 따라 더 가능성이 높은 범주에 속하도록 분류해주는 학습 알고리즘이다.
(스펨메일 분류나 시험 합격 여부 등이 있다.)
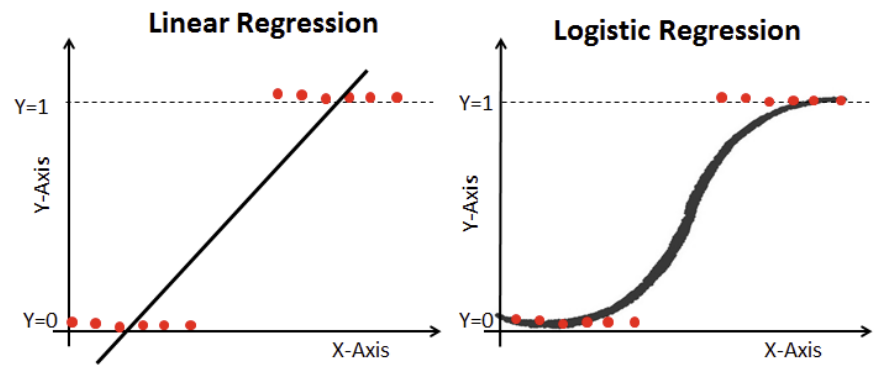
공부 시간에 따른 시험 합격 가능성을 예로 들어보면, 다음은 선형회귀로 나타낸 그림이다.

공부시간이 적으면 합격할 확률이 낮아지고, 공부시간이 많으면 확률이 높아진다.
그림은 선형회귀로 표현했기에 확률이 양,음의 방향으로 무한대로 뻗어나간다. (확률을 음수나 1을 초과해서 표현할 수 X)
이를 로지스틱 회귀로 나타내면, 아래 그림과 같다.
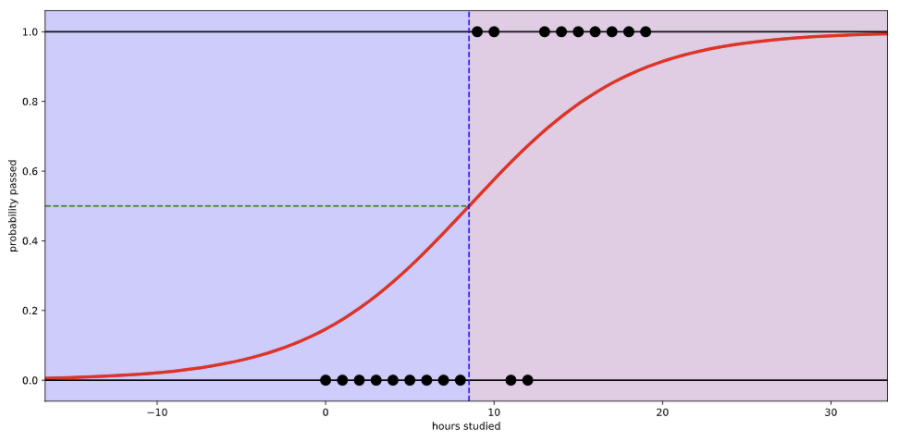
로지스틱 회귀로 표현하여 합격 확률이 0~1 사이로 표현된다.
로지스틱 회귀에서는 데이터가 특정 범주에 속할 확률을 예측하기 위해
1. 가중치와 입력을 계산한다. (선형함수 계산) 로지스틱 회귀는 z를 임계함수로 보내기전에 변형시킨다.
2. 시그모이드 함수(활성화 함수)에 넣어서 0~1 사이의 확률을 구한다.
3. 임계함수를 이용하여 입력데이터를 0 또는 1로 분류한다.
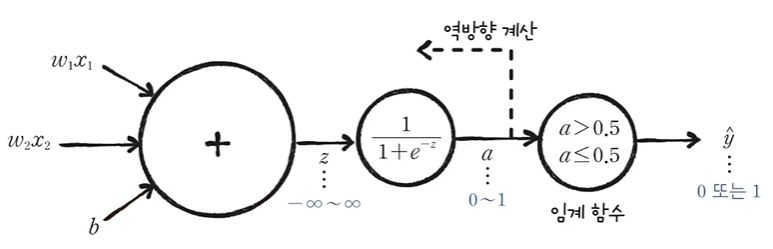
퍼셉트론(Perceptron)
이진 분류 문제에서 최적의 가중치를 학습하는 알고리즘이다.
이진분류(binary classification)이란 임의의 샘플 데이터를 True 나 False로 분류하는 문제를 말한다.
퍼셉트론은 선형 회귀와 마찬가지로, 직선 방정식을 사용한다. 퍼셉트론은 마지막 단계에서 데이터를 이진분류하기 위하여 계단 함수(step function)를 사용한다. 이 계단함수를 통과한 값은 가중치와 절편을 업데이트시키는데 사용된다.
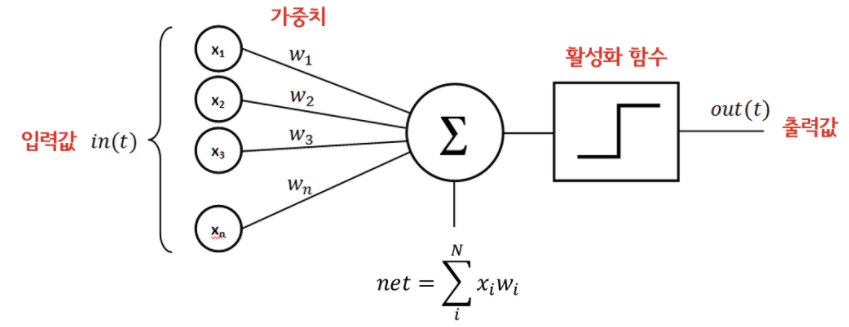
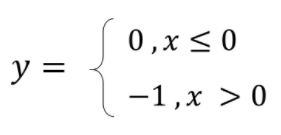
계단함수는 0을 기준으로 분류한다.
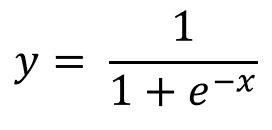
활성화 함수로는 다음과 같은 비선형 함수를 사용한다.
로지스틱 회귀는 이진분류하는 것이 목표이므로, (-무한대, 무한대)의 값을 갖는 z의 값을
활성화 함수인 시그모이드 함수는로 z를 0~1사이의 확률값으로 변환시켜 준다.
로지스틱회귀에서는 가중치와 절편을 업데이트 해주기 위해 로지스틱 손실함수를 사용한다.
(선형회귀에서는 손실함수로 제곱 오차를 사용했었다)
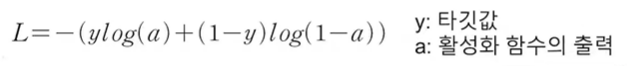
선형회귀 : 정답과 예상값의 오차 제솝이 최소가 되는 가중치와 절편을 찾는 것이 목적
로지스틱회귀 : 올바르게 분류된 데이터의 비율을 높이는 것이 목적
'ML > 딥러닝 입문' 카테고리의 다른 글
| 04. 다층 신경망 (0) | 2022.02.04 |
|---|---|
| 03. 과대적합, 과소적합과 규제 방법 (0) | 2022.01.31 |
| 01. [선형회귀] 수치 예측 (0) | 2022.01.10 |